利活用検討部会での検討内容
大規模植生調査データの活用に向けて -群集・群落区分の正当性評価-
※本検討は利活用検討部会委員である鎌田磨人教授(徳島大学大学院ソシオテクノサイエンス研究部)および前田将志氏(徳島大学工学部建設工学科)が実施した。
実施期間・業務名など
平成23年度自然環境保全基礎調査植生調査業務 利活用検討ワーキング
概要
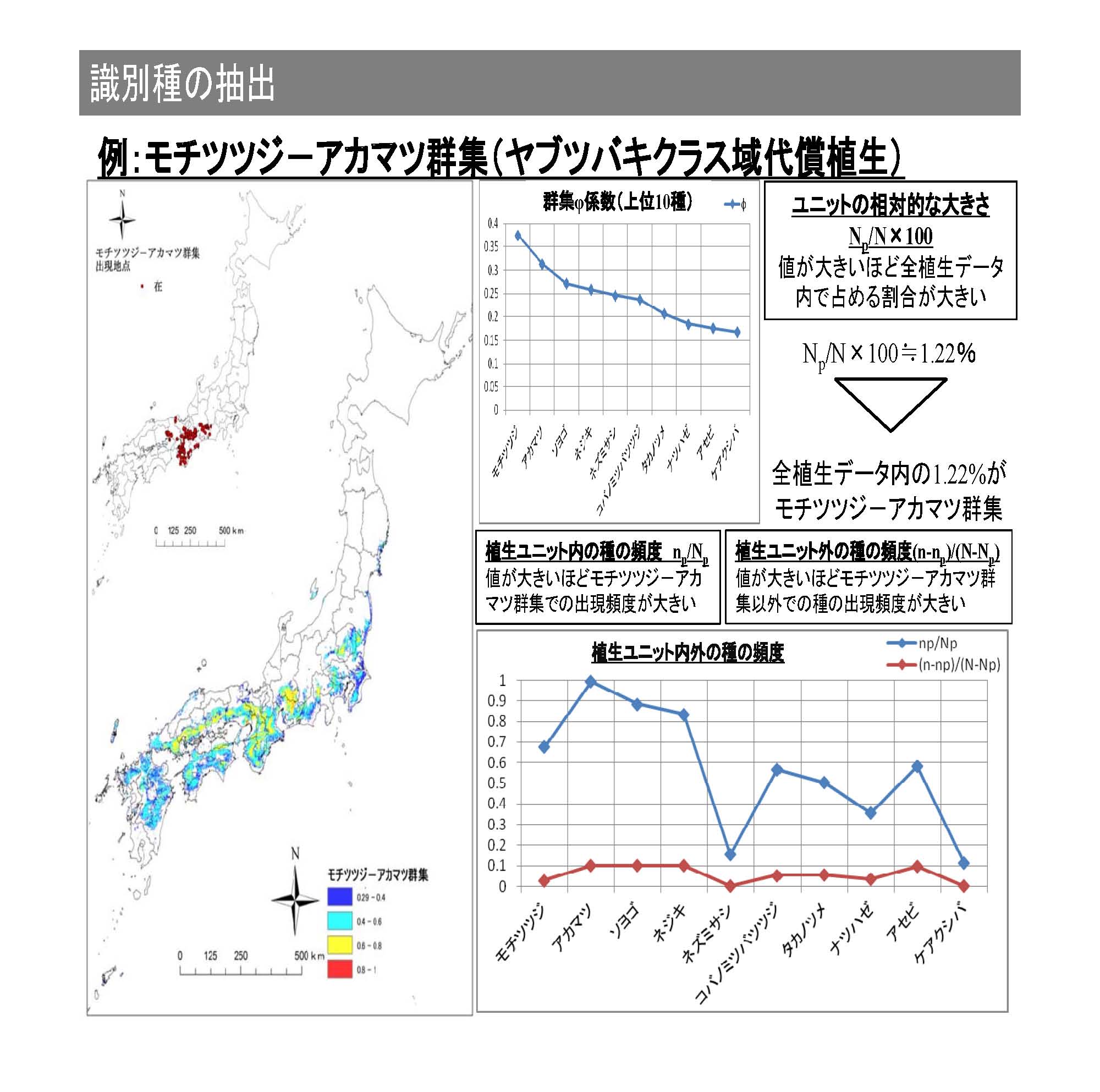
1.背景・目的
環境省では日本全国を対象に、自然環境保全基礎調査植生調査を行っており、植生調査に基づき植生凡例が決定され、地図化されている。このような統一的手法による大規模調査は、日本以外のアジアでは行われていない。一方、ヨーロッパ諸国では、植生調査資料の大規模データベースが構築され、活用されている。その一つが、そのデータベースを用いて、識別種の正当性を統計的に再評価していこうとする動きである。
ヨーロッパと同様、日本の植生図も植物社会学的な体系によって群集・群落区分されている。そのため、植生調査による組成データを用いた識別種や群集・群落区分の正当性を、統計的な手法に基づき再評価しておくことは、植生学上の意味を持つだけでなく、今後の植生図作成業務を遂行していく上でも重要である。本検討では、森林群集・群落として与えられている53凡例の植生調査資料を用いて、統計的な手法によって識別種の抽出が可能であるかどうかを検討した。
2.方法
自然環境保全基礎調査植生調査データから森林として成立する53凡例を抽出し、その群集・群落と種の在データを作成した。そして、それぞれの種に対して群集φ係数を算出し、Fidelityを測定した。なお、群集・群落内で群集φ係数値が高い種は、その群集・群落を特徴づける種とされ、Fidelityとは種の共起情報を意味する。
次に、各群集・群落内の群集φ係数上位10種を用いてクラスター分析を行い、類型化を行った。その際、群集φ係数上位10種にはレッドリスト種、シノニムなどが含まれていないかを確認することで、群集・群落を特徴づける種を評価した。
3.結果
高いφ係数の値を持つ(識別種として意味を持つ)種を含む群集・群落があった。その一方で、異なった凡例は与えられてはいるものの、φ係数値が低く他の凡例とも共通する種しか抽出できないような群集・群落もあることが判明した。特に、二次林では、明瞭な識別種を抽出することが困難であった。
なお、現在のデータベースでは、シノニムで標記されている種や、属レベルでの同定による標記(~sp)も混在している。データベースとして広く活用を進めていくためには、こうした種の記載方法や取り扱いに対しての方針を策定しておく必要がある。環境省のイニシアティブによって蓄積されてきた大規模植生調査資料の重要性を深く認識し、改善・工夫をしながらデータベース化を行い、およびその活用方法の構築、さらには国土モニタリングシステムへの発展を目指していく必要がある。